Algorithmic Harms and Types of Bias
Algorithmic Biases and De-Biasing Data

A Typology of Algorithmic Harms
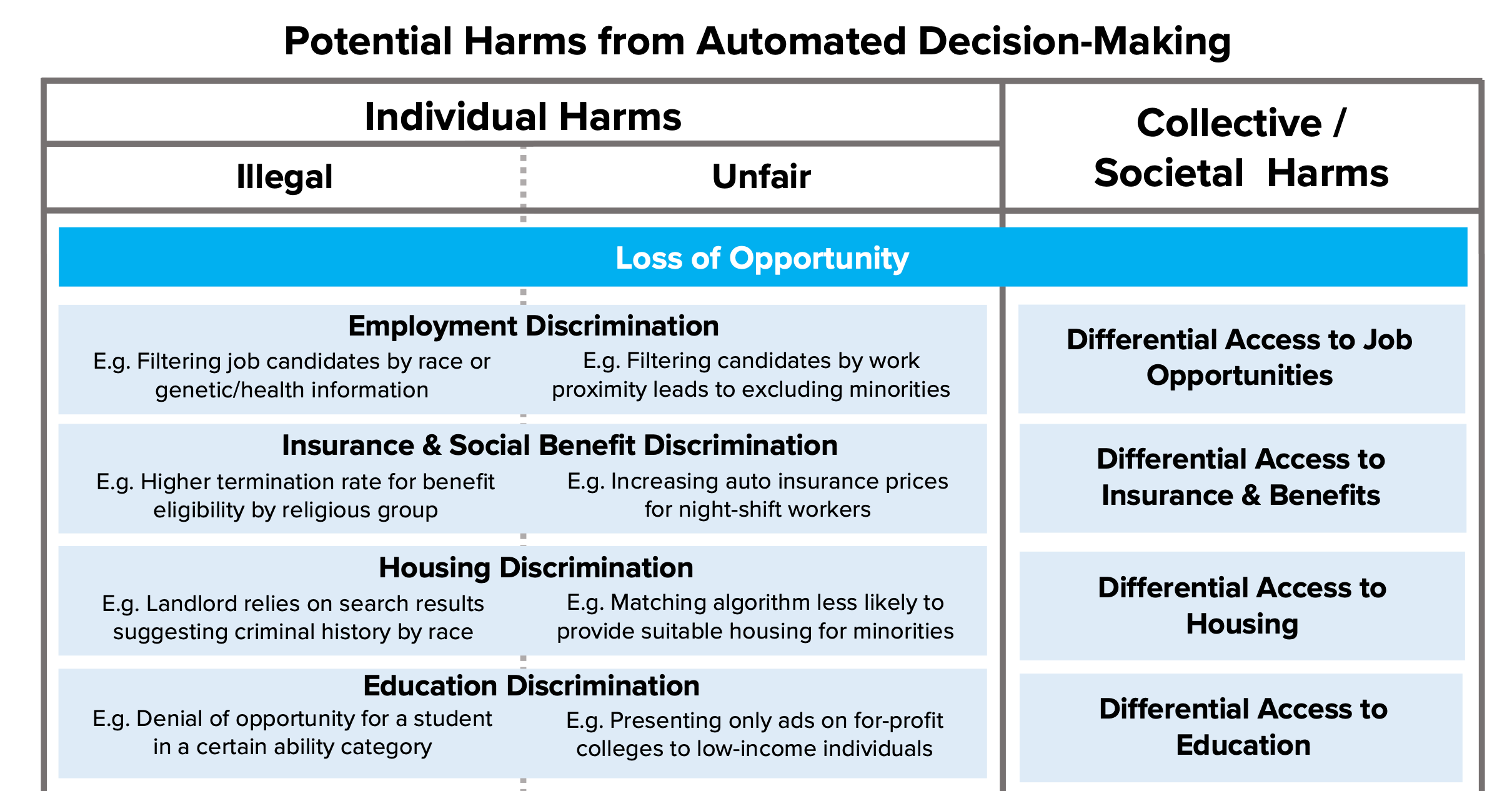
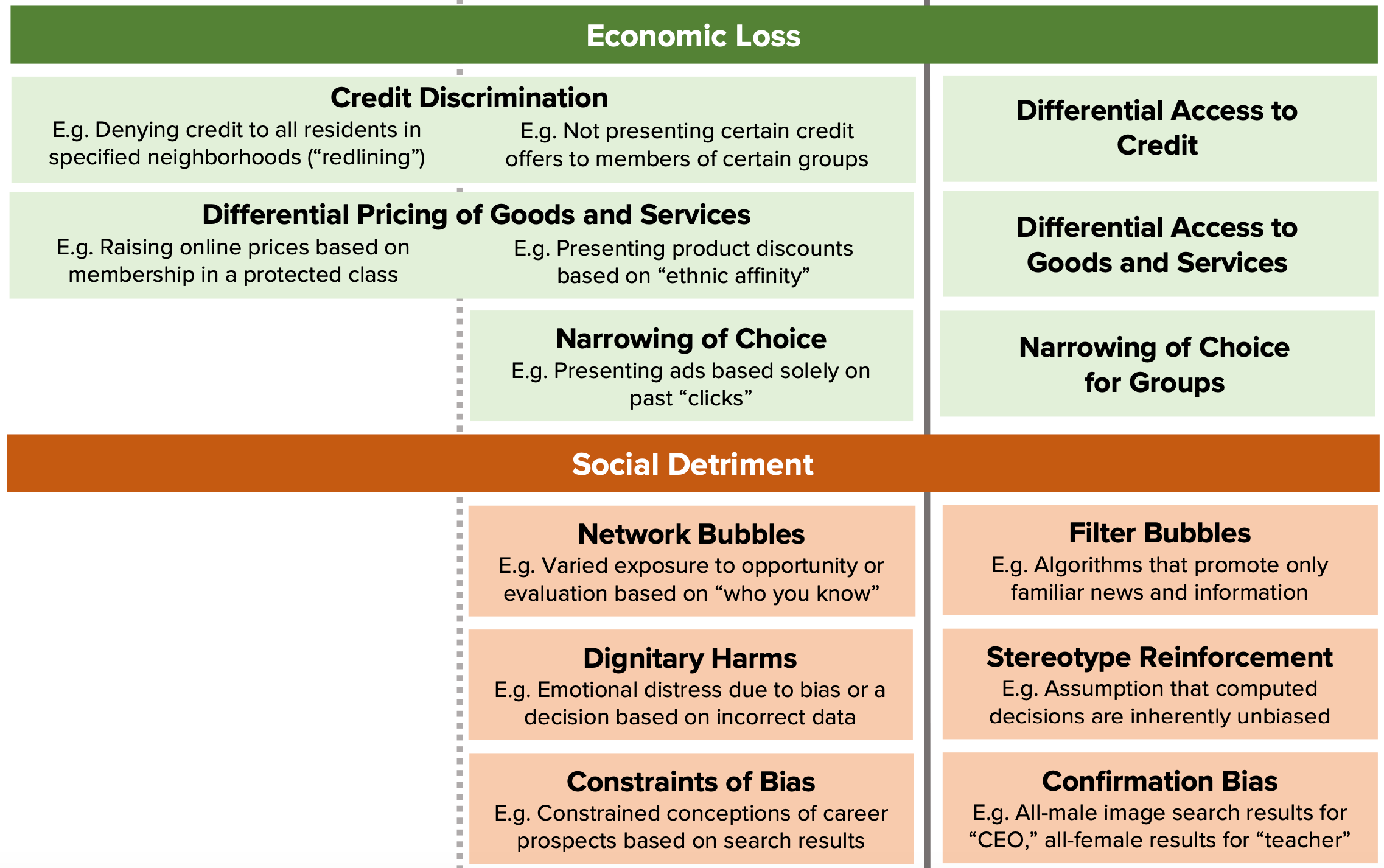
The future of privacy forum offers this handy chart in classifying algorithmic harms into 4 dimensions - loss of opportunity, economic loss, social detriment, and loss of liberty. I will focus on how the use of automated decision making rules in a business context could lower opportunities (and thereby limit economic mobility) as well as erode the economic wellbeing of individuals.
Economics of Search Costs and Transaction Costs
From an economics perspective, every digital transaction we take part in involves search costs and transaction costs. We incur different types of search costs -be it the cost of searching for what movie to watch or job seekers incurring opportunity costs in finding employment opportunities suited to their experience and one that is sufficiently worthwhile for them to undertake. We also incur search costs when we look for what car to purchase or even which set of friends to hang out with (maybe virtually due to the pandemic)!
For decades, advertisers and marketers grappled with the challenge that it is difficult to predict consumption of leisure products such as movies and books. Tastes are highly subjective and the elements of plot and narrative that make one movie a tremendous hit could easily make another a critical and commercial failure. Equally challenging is deciding the timing. How do studios decide which weekend to release a movie? When a publisher releases a hard copy of a book, how do they decide when to release the e-book version? Or the problem that my co-authors and I attempted to study -we know who is likely to be interested in buying a product, but at what time? At the same time, consumers also grappled with significant search costs in making choices involving time and money (or both).
Most economic transactions rely either on the market or bilateral actors to provide an assurance that the contracted upon obligations will be met. Accordingly, much of research that looks at interfirm transactions has highlighted the potential for opportunism that arises from one party’s incentives in deviating from what is agreed upon. Opportunism can result either from a seller’s gains from holdup or a buyer’s gain in shirking from relational obligations. Such opportunism creates transaction costs in engaging in the market -be it the cost of matching buyers and sellers, the costs of planning, executing, negotiating, fulfilling a transaction and even dealing with disputes as they may arise.
With AI and big data, marketers and technology companies alike have unprecedented visibility into both search and transaction costs. Thanks to AI and the Internet, streaming shows acquire a larger audience than what is economically feasible for distribution through primetime Television. Since streaming media companies such as Netflix do not have the high fixed costs of studios and the costs of distribution in movie theaters, they can produce more number of shows that cater to a niche audience. With real time data mined from social sites such as Twitter, fansites, Instagram, movie review sites etc., studios have their pulse on what movie goers are saying about which movie, show or song. AI provides us better visibility into what books are read and which shows are likely to be binge watched. When a company such as Amazon decides which books to recommend to potential readers, or which Prime shows to produce, they have detailed digital traces of what points of the plot and narrative engaged audiences and what did not.
Algorithmic Search Costs
So much of the hype around AI is that it lowers the frictions from search and transaction costs by offering a greater menu of choices for individuals. At the same time, we have to worry about widening of disparities along two dimensions: disparate impact and disparate treatment. The key issue around bias detection and mitigation is whether algorithmic governance poses differential costs to different groups. In other words, using AI in mortgage processing might lower the overall costs to a bank, but in the process, does AI create a hidden set of search costs and transaction costs that place undue burdens on different groups of individuals?
The Department of Housing and Urban Development launched a probe of Facebook’s targeted advertising platform, alleging that it violates the Fair Housing Act, “encouraging, enabling, and causing” unlawful discrimination by restricting who can view housing ads. The HUD charged that Facebook’s ability to micro target its users through advertising implied that characteristics protected by law, such as race, color, national origin, religion, familial status, sex and disability, were used to determine who can view housing ads. In effect, different types of users were shown different ads depending on their demographic profile. In response to this and other complaints, Facebook agreed to overhaul its ad targeting systems. Google likewise announced it was changing some of the personalized advertising policies on its site, wherein entities placing ads for employment, housing, or credit services from targeting or excluding ads "based on gender, age, parental status, marital status, or ZIP Code." A different ProPublica investigation found that many companies were using Facebook to exclude older workers from job ads.
Quoting the Propublica Report:
“Verizon placed an ad on Facebook to recruit applicants for a unit focused on financial planning and analysis. The ad showed a smiling, millennial-aged woman seated at a computer and promised that new hires could look forward to a rewarding career in which they would be “more than just a number.””
“The promotion was set to run on the Facebook feeds of users 25 to 36 years old who lived in the nation’s capital, or had recently visited there, and had demonstrated an interest in finance. For a vast majority of the hundreds of millions of people who check Facebook every day, the ad did not exist.”
A recent example in the Markup highlighted that Google’s advertising system may have enabled employers or landlords to discriminate against nonbinary and some transgender individuals.
These are examples of how algorithmic decision making create huge invisible search costs (which are disparate in their impact for different groups of people), raising the costs of job search or house hunting for groups of individuals. At the extreme, it is as if algorithmic decision making is rendering categories of individuals entirely absent from swathes of economic activity.
Picture if you will, a 50 year old woman, Charlene, who belongs to a minority community and lives in a zip code classified as high risk for burglary. Charlene could have excellent credit history and a solid employment record of 25+ years. However, for the algorithms underlying the Facebook’s personalized feeds, she is invisible, cloaked as it were in her racial and gender identity that make her lived experiences opaque to the algorithm. Disparate impacts as a result of algorithmic decision making can then amount to de facto redlining, placing an invisible cost on more disadvantaged communities. Taken at the aggregate, these types of visible as well as invisible search costs place disproportionate burdens on different segments of society, making it difficult for someone to find a job, move to better housing, creating a self-reinforcing spiral of poverty and limited upward mobility.
De-Biasing Metrics for Algorithmic Harms and Proxy Discrimination
It is not as if there are no ways to address these algorithmic harms. , researchers have proposed a method called conditional demographic disparity (CDD) -defined as “the weighted average of demographic disparities for each of the subgroups, with each subgroup disparity weighted in proportion to the number of observations it contains.” This implies for example that if women comprised 60% of the rejected applicants but only 50% of the accepted applicants, there is demographic disparity because the rate at which women were rejected exceeds the rate at which they are accepted. Such a disparity metric would serve to highlight whether something that appears to be biased may not in fact be a bias. For example, as highlighted by the researchers, there is the well known phenomenon of Simpson’s Paradox where the overall data from Berkeley admissions showed that men were accepted at a higher rate overall than women. However, it turned out that women had applied to departments with lower acceptance rates. When looking at the subgroup acceptance rates, women were accepted at higher rates than men for the departments with low acceptance rates.
Another area of concern is what is termed proxy discrimination -wherein AI decision making models will not use characteristics that are legally protected; rather, they will end up using characteristics that are highly correlated or connected with the legally protected characteristic. An excellent review article by Prince and Shwarcz highlights three types of proxy discrimination -(i) causal when a legally-prohibited trait is causally linked to a desired outcome, (ii) opaque when it is correlated to a desired outcome, but its predictive character is not mediated through a presently quantifiable or available variable and (iii) indirect due to indirect connections between prohibited traits and target variables.
Different types of Proxy Discrimination: Figure from Prince and Schwarcz
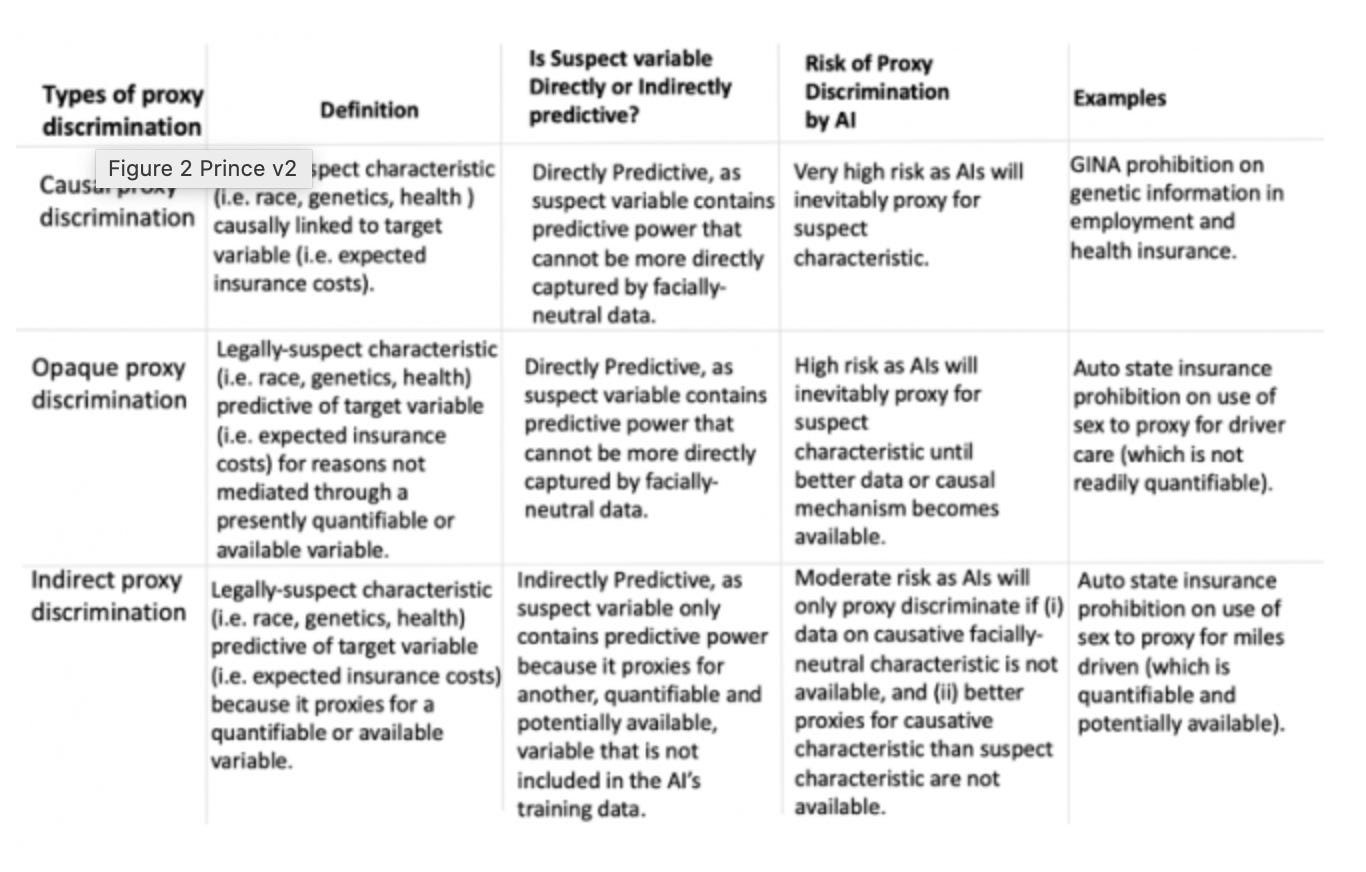
A Dutch court recently halted the deployment of algorithmic oversight of welfare fraud, since it was primarily targeting neighborhoods with low-income and minority individuals. New regulations unveiled by European Union’s data protection rights framework, General Data Protection Regulation (GDPR), gives individuals the right not to be subject solely to automated individual decision-making. Needless to say, employment law and other aspects of the law will have to carefully examine the disparate impact as well as disparate treatment from algorithmic decision making. The issue of algorithmic transaction costs are reserved for a future post.
Sources of Bias -Training Data, Availability Heuristics and Complex Feedback Loops
So let us dig a little into what are some sources of biases caused by automated decision making. While there can be several sources of bias, I will focus primarily on (i) biases due to issues with training data (such as the Amazon recruiting tool example explained in a previous post), and (ii) cognitive biases, such as availability heuristics, that are magnified with AI.
As explained earlier, Machine Learning is a branch of AI that is concerned with the design and development of algorithms that allow computers to interpret behaviors based on observed data. Let us take a quick detour into supervised learning, testing and training. A machine’s learning algorithm enables it to identify patterns in observed data, build models that explain the world, and predict things without having explicit pre-programmed rules and models. Below is a simplified representation of how machine learning works.
Testing and Training (from the Machine Learning Cookbook)
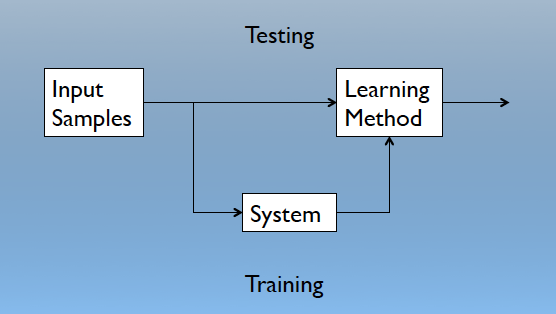
We use a set of data called training data to learn features in order to predict an outcome.
Training is the process by which we ensure that the observed data is consistent with that of a universal set of unobserved data. Training can be defined is the process of making the system able to learn. We implicitly assume that the testing dataset and the training dataset obey the same distributional assumptions (this is referred to in machine learning as no free lunch principle).
In general, the performance of ML algorithms depends on the type of training data and the quality and accuracy of labeled data (for supervised learning), the type of feedback mechanism (that allows algorithms to iteratively learn) and the method of learning itself (that underlie the algorithms used).
The main two types of machine learning algorithms used are supervised learning and un-supervised learning. In recent years, a branch of ML referred to as self-supervised learning has been responsible for dramatic improvements in the performance of AI to decode spoken text, image recognition, automated translation etc. If we are interested in predicting how much revenue will be generated by social media campaigns, would a particular individual graduate from college or drop out, the market sentiment upon stock market opening on a given day, these are are different types of prediction problems wherein we use supervised learning. In supervised learning problems, we start with a data set that contains training data that is labeled. For example, when we want to use supervising learning algorithms to decoding doctors’ case notes that form part of electronic medical records (EMR), the supervised learning algorithm needs to decode the association between clinical symptoms, which could be done through labeled dataset where a vocabulary of clinical terms. The algorithm is then training itself to recognize associations between doctors’ descriptions and a typology of clinical terms, and can then be used on a completely new dataset to predict the likelihood of particular patients being at risk for cardiac arrest, depression etc. When a new patient is admitted to the ER, we could deploy such an algorithm to classify what treatment the patient should receive, the level of monitoring and care they should receive etc. Supervised machine learning learns to identify patterns in the data in a somewhat context-agnostic fashion where we can provide a labeled training dataset and validate the results with a test data, and then generalize these predictions to a broader (and newer) unlabeled sample.
Different Types of Biases
As I mentioned earlier, two types of biases can be introduced in such a scenario as above. First, we are learning to generalize from training data, therefore biases creep in when training data does not generalize to the overall population or when the training data is suffused with racial and gender biases that are prevalent in the real world (such as the Amazon recruiting tool example explained in a previous post).
It follows that that some of the sources of bias come from how we can extrapolate from the training dataset, where we could end up classifying someone as less sick than they really are based the amount of healthcare resources they have used, categorize someone as more likely to commit another crime based on where they live, or less likely to be interested in employment opportunities based on their age or gender. De-biasing methods are important, but so are methods that allow human input into complex cycles of feedback.
Machine learning methods are designed to avoid overfitting: learning a function that perfectly explains the training data that the model learned from, but doesn’t generalize well to unseen test data. Overfitting happens when a model overlearns from the training data to the point that it starts picking up idiosyncrasies that aren’t representative of patterns in the real world. We refer to this as the Bias-Variance tradeoff where we need to tradeoff the amount of error from approximating real-world phenomenon (wherein there is a danger of oversimplifying) with that of how well the our predictions depend on the variance of the idiosyncratic data the models were trained on (where the danger is that we can explain the training data very well but cannot generalize beyond that). Therein lies the conundrum and the challenge with deploying large scale automated decision making. Recognizing when a human decision maker is needed and when automated decisions can be employed will be increasingly important as we learn to navigate the algorithmic era. It has been suggested that automation in the processing of mortgage applications could pose several biases, since they could end up learning or mimicking the historically unfair and discriminatory policies. It was observed that when Microsoft unveiled a conversational AI chatbot that was trained with Twitter data, the chatbot taught itself to become racist and sexist, mainly because its method of learning was to parrot what its users said.
The second type of biases creep in due to complex biases in society, such as availability heuristics, of the algorithmic designer. This can lead to complex feedback loops when individuals can modify their behavior as a result of AI. When predicting recidivism, we are attempting to measure who is likely to re-commit a crime, but the data we have are about who is likely to get re-arrested. It is important to note that some types of automated decisions can also reverse these types of biases. Automobile insurance typically charges higher rates for younger men than younger women, with the assumption that the former are more likely to be risky drivers. With the widespread adoption of telematics technologies, it becomes easier to observe the quality of driving (speeding in a low speed done, scores for harsh braking etc), so it becomes possible to charge insurance prices on the type of driver behavior, rather than engage in proxy discrimination).
An entirely different type of result can be seen in financial markets where automated trading and quantitative analysis has led firms to change their disclosures and filings to be compliant to machine parsing and processing. British Economist Charles Goodhart made this observation (referred to as Goodhart’s law) that “Any observed statistical regularity will tend to collapse once pressure is placed upon it for control purposes.” The more there is scrutiny of some types of causal links in the data, the more individuals and firms will change their behavior as a result of it.
In life as well as in building AI, there may be no silver bullet to dealing with biases. However, we need to keep in mind (i) it is important to de-bias training data, (ii) we need to deploy automated decision making in tandem with human input, (iii) the solution to some types of biases may be better and different types of data gathering, and (iv) complex feedback loops imply that focusing too much on a narrow set of metrics, even if they are debiased and interpretable, renders them less relevant.